首页
区块链
后端
Java
Linux
归档
程序员小柯
没有你学不会的,只会是你不想学
累计撰写
9
篇文章
累计创建
5
个标签
累计收到
1
条评论
栏目
首页
区块链
后端
Java
Linux
归档
目 录
CONTENT
最新文章
2024-11-02
区块链入门到放弃
知识 solidity 视频教程:https://www.bilibili.com/video/BV1HR4y197Ag?spm_id_from=333.788.videopod.episodes&vd_source=5ca2389109f3795f3ebaa15eda304560
2024-11-02
239
1
0
区块链
2024-03-08
Java基础之删除list中的某个元素
List<String> list = new ArrayList<>(); list.add("小白"); list.add("jack"); list.add("小强"); list.add("jack"); // 删除 jack list.removeIf(next -> next.equa
2024-03-08
4449
0
0
Java
2024-03-08
Java实现JSON Web Token(JWT)的生成、解码和验证
JSON Web Token(JWT)是一种用于安全传输信息的开放标准。它可以用于认证和授权用户,以及在不同系统之间传输数据。在本文中,我们将介绍如何在 Java 中使用 jjwt 库来生成、解码和验证 JWT 引入 jjwt 库 首先,你需要在你的项目中引入 jjwt 库。如果你使用 Maven,
2024-03-08
4227
0
1
Java
2024-03-08
SpringBoot AOP实现统一日志处理
在基于Spring Boot的项目开发中,日志记录是一个非常重要的方面。为了规范和简化日志记录的过程,我们可以利用Spring Boot的AOP(面向切面编程)功能来实现统一的日志处理。 首先,我们需要创建一个切面类,并使用 @Aspect和 @Component注解进行标识。切面类的作用是定义切点
2024-03-08
4037
0
0
Java
2024-03-08
使用 Spring Boot 和 DTO 进行数据验证
Spring Boot 是一个非常流行的 Java Web 应用程序开发框架,它提供了很多方便的功能,让开发者可以快速构建出高效、安全的 Web 应用。在开发 Web 应用程序时,数据验证是非常重要的一环。通过使用 DTO(Data Transfer Object)来验证数据,可以确保应用程序中输入
2024-03-08
4081
0
0
Java
2024-03-08
SpringBoot实现登录校验验证码
在开发Web应用程序时,用户登录功能是一个常见的需求。为了增加安全性,我们可以引入验证码来进行登录校验。本文将介绍如何使用Spring Boot框架实现登录校验验证码的功能。 首先引入依赖 <dependencies> <dependency> <group
2024-03-08
3673
0
0
Java
2024-03-08
全国职业院校技能大赛-区块链技术应用(1卷)-区块链系统部署与运维
任务1-2:区块链系统部署与运维 子任务1-2-1: 搭建区块链系统并验证 采用默认配置搭建区块链网络 使用 build_chain.sh在本机搭建一条4节点区块链系统,-l指定IP,-p指定端口,-e指定本地 fisco-bcos,不指定则去GitHub自动下载 [root@localhost t
2024-03-08
3225
0
4
区块链
2024-03-07
全国职业院校技能大赛-区块链技术应用(4卷)-区块链系统部署与运维
任务1-2:区块链系统部署与运维 通过给定区块链项目需求,进行区块链系统部署,包括系统部署、控制台部署等。通过监控工具完成对网络、节点服务的监控。最终利用业务需求规范,完成系统日志、网络参数、节点服务等系统结构的维护。 部署区块链服务器,配置管理平台参数及访问端口; 部署项目节点,获取管理平台与节点
2024-03-07
3036
0
5
区块链
2024-03-07
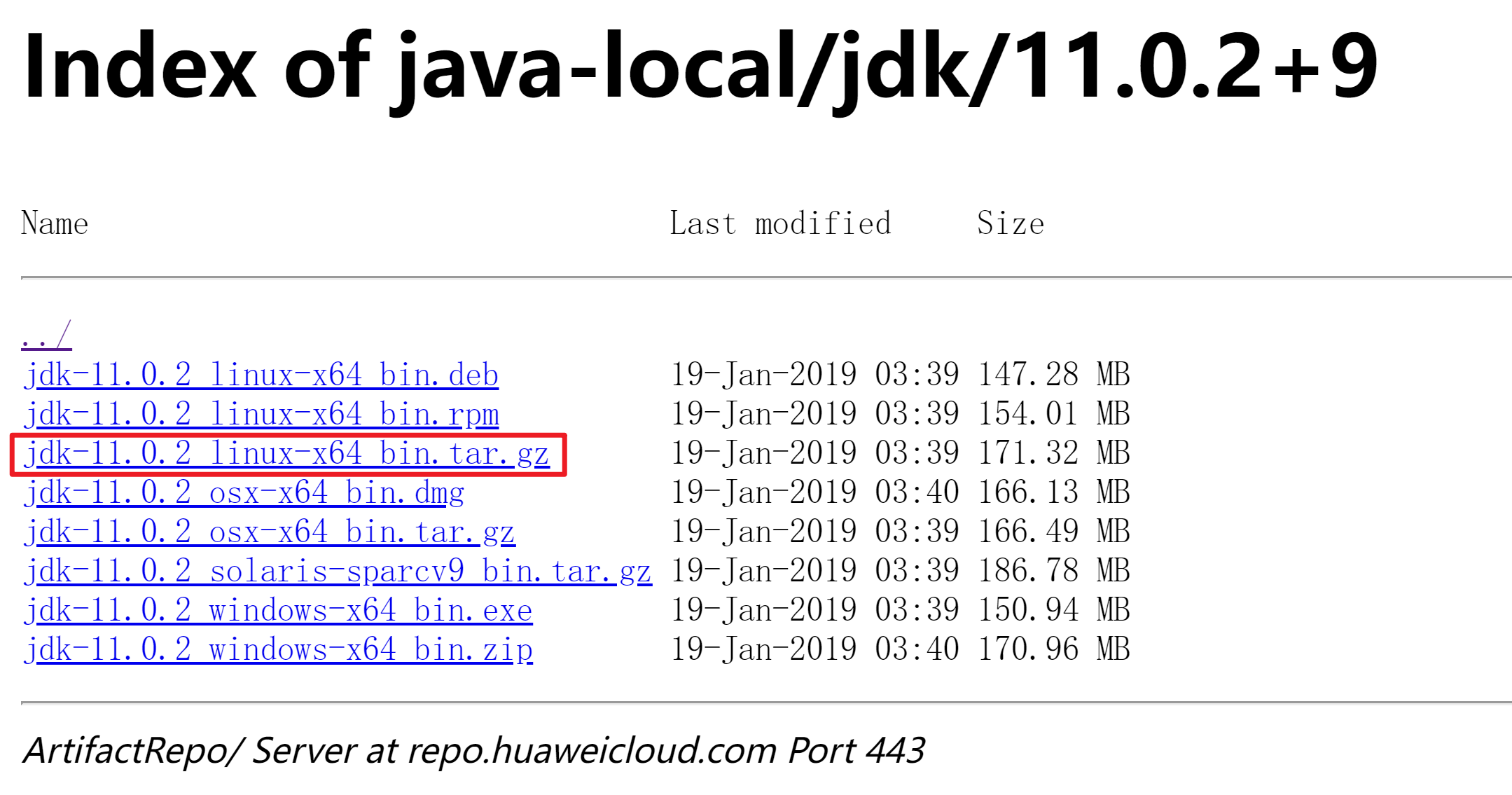
CentOS7.6 上安装 JDK 11
OpenJDK 是 Java 编程语言的开放源代码实现。在 CentOS 上安装 OpenJDK 可以为您提供一个稳定和可靠的 Java 开发环境。本文将指导您通过几个简单的步骤在 CentOS 7.6 上安装 OpenJDK 11。 1.下载JDK11 国内华为镜像下载:https://repo.
2024-03-07
2846
0
2
Linux